DeepSeek-V4-Flash Chegou ao Ollama
DeepSeek-V4-Flash Chegou ao Ollama
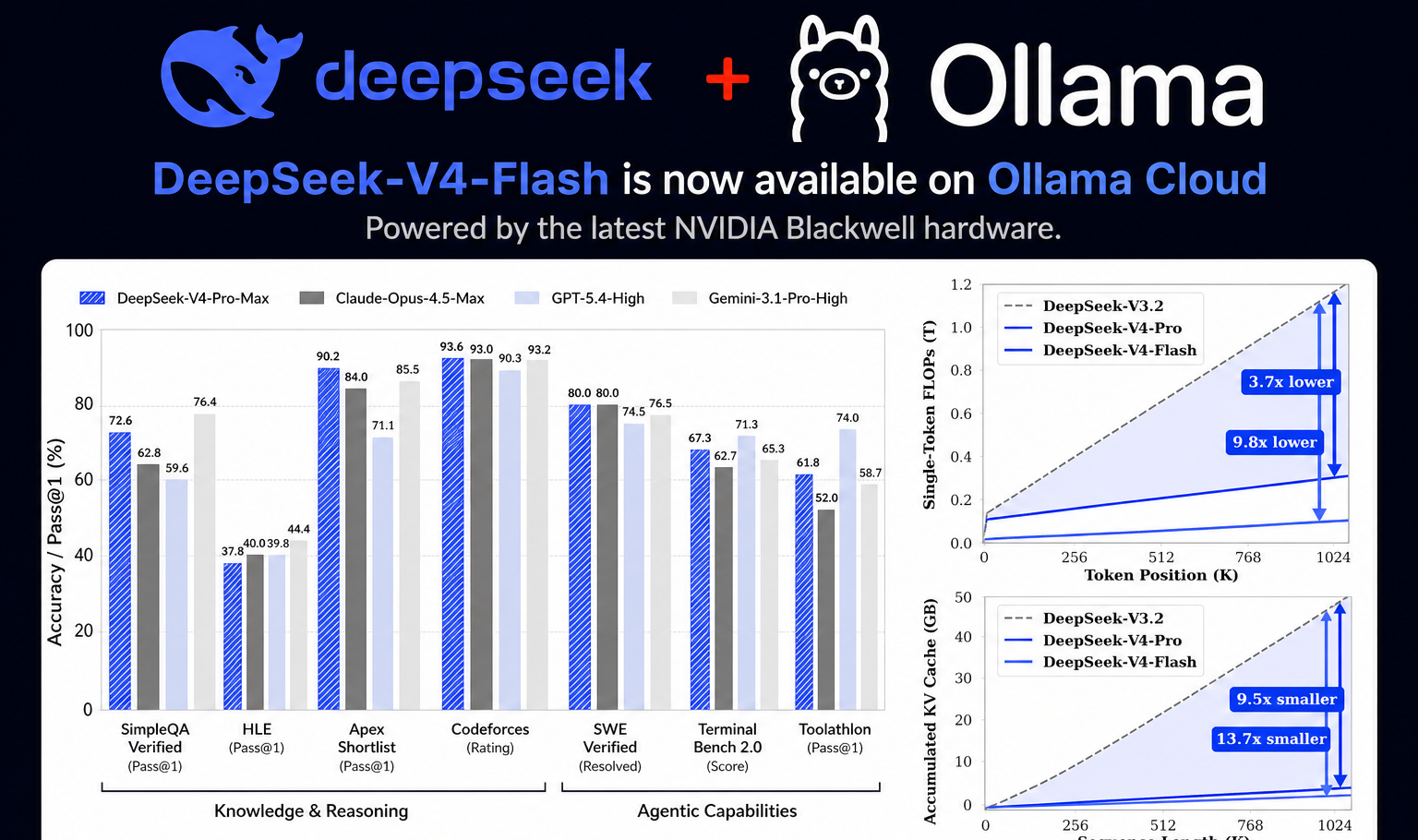
A nova geração de modelos da DeepSeek chegou com uma proposta clara de escala sem desperdício. O DeepSeek-V4-Flash, está disponível via Ollama Cloud com as GPUs NVIDIA Blackwell, ele traz uma arquitetura Mixture-of-Experts (MoE) com 284B de parâmetros totais, mas usando apenas 13B ativos por inferência.
Na prática é um desempenho de modelo gigante com custo e latência muito mais controlados.
O que é o DeepSeek-V4-Flash?
O V4-Flash é uma prévia da série DeepSeek-V4, projetada para tarefas complexas de raciocínio e contexto longo.
Principais características:
- Arquitetura MoE (eficiência computacional)
- 284B parâmetros totais / 13B ativos
- Janela de contexto de até 1 milhão de tokens
- Otimizado para raciocínio estruturado e agentes
Isso permite lidar com código extenso, logs massivos e pipelines inteiros sem fragmentação de contexto.
Rodando com Ollama
A integração com Ollama simplifica completamente o uso em ambiente local + cloud híbrido, exemplos de como usar com o Ollama:
Executar diretamente:
ollama run deepseek-v4-flash:cloud
Com Claude Code:
ollama launch claude --model deepseek-v4-flash:cloud
Com OpenClaw:
ollama launch openclaw --model deepseek-v4-flash:cloud
Com Hermes Agent:
ollama launch hermes --model deepseek-v4-flash:cloud
Por que isso importa?
Modelos grandes sempre tiveram um problema o custo operacional.
O MoE resolve isso ativando apenas partes do modelo por tarefa — mantendo qualidade alta com uso eficiente de GPU.
Resultado direto:
- Menor custo por inferência
- Maior escalabilidade
- Melhor latência em cenários reais
Casos de uso
- Análise de código em larga escala
- Agentes com memória extensa (long context)
- Processamento de logs e dados massivos
- Orquestração de workflows complexos
- Sistemas multi-agente com contexto compartilhado
O que vem a seguir
O DeepSeek-V4-Pro já está no roadmap e deve expandir ainda mais capacidade e estabilidade para produção.
Conclusão
O DeepSeek-V4-Flash não é só mais um modelo grande é um passo técnico importante na direção de IA escalável de verdade.
Se você trabalha com agentes, automação ou engenharia de IA, esse tipo de arquitetura (MoE + long context) tende a virar padrão.
Menos hype, mais throughput.
Referências:


